





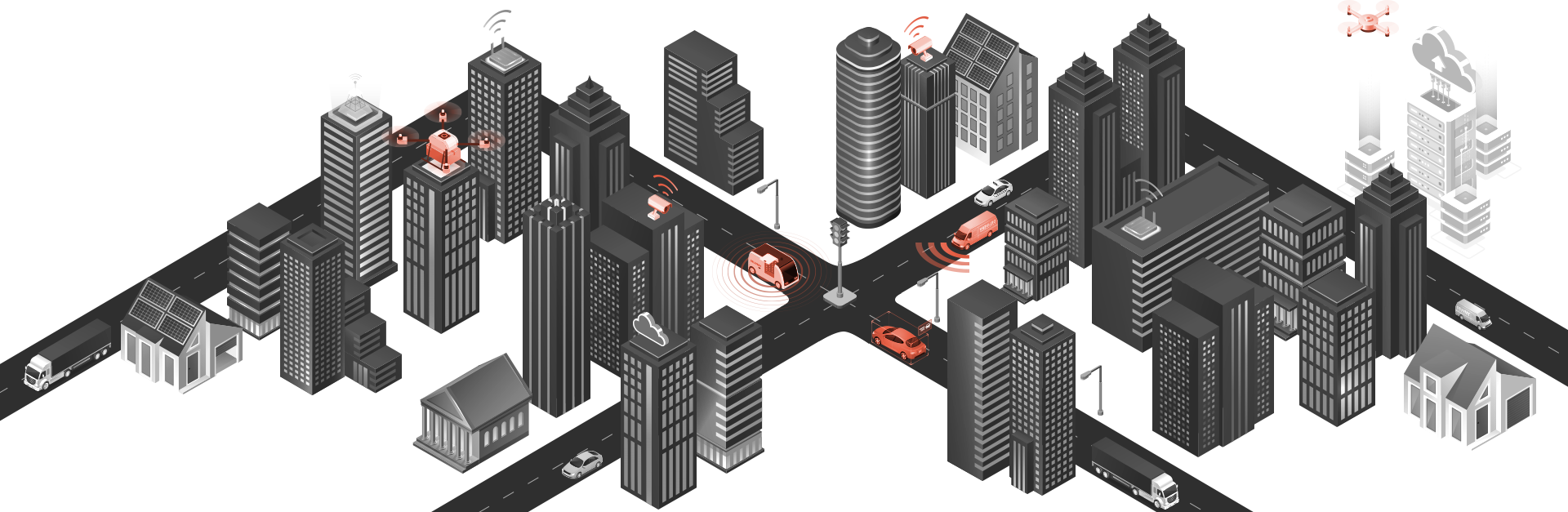
应用场景
APPLICATION SCENARIO

芯片产品
CHIP PRODUCTS
- DeepEye1000
- DeepEdge10C
- DeepEdge10
- DeepEdge10Max

DeepEye1000
面向计算机视觉的深度学习神经网络处理器芯片
内置自研CNN网络加速引擎,可以实现高性能低功耗的CNN网络模型的加速
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
规格参数 +

DeepEdge10C
面向计算机视觉的深度学习神经网络处理器芯片
内置自研CNN网络加速引擎,可以实现高性能低功耗的CNN网络模型的加速
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
规格参数 +

DeepEdge10
面向计算机视觉的深度学习神经网络处理器芯片
内置自研CNN网络加速引擎,可以实现高性能低功耗的CNN网络模型的加速
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
规格参数 +

DeepEdge10Max
面向计算机视觉的深度学习神经网络处理器芯片
内置自研CNN网络加速引擎,可以实现高性能低功耗的CNN网络模型的加速
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
提供强大的可编程运算能力,满足CNN算法实时性处理的运算要求
自定义指令集和编程框架,支持主流的CNN算法移植,如人脸识别等,以及其他计算机视觉CNN算法的移植和应用
可广泛应用于智能摄像机、工业检测、机器人、无人机等领域
神经网络处理器
自研神经网络处理器 NNP400T;
提供 8 TOPS (INT8)/4 TOPS (INT16)/ 1.5 TFLOPS (FP16) 的算力;
支持常用深度学习网络,如:CNN,RNN,Transformer,GNN 等;
规格参数 +
模组&卡
MODULE & CARD
- 模组 IPU X100
- 模组 IPU X200
- 模组 IPU A300
- 卡 IPU X1000
- 卡 IPU X2000
- 卡 IPU X5000

模组 IPU X100
采用云天励飞自研神经网络处理器芯片 DeepEye1000
配备 DDR4-2667,16GB,NNP 主频 1GHz
配备 DDR4-2667,16GB,NNP 主频 1GHz
支持 24 路 1080P H.264/H.265 高清视频解码
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
规格参数 +

模组 IPU X200
采用云天励飞自研神经网络处理器芯片 DeepEye1000
配备 DDR4-2667,16GB,NNP 主频 1GHz
配备 DDR4-2667,16GB,NNP 主频 1GHz
支持 24 路 1080P H.264/H.265 高清视频解码
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
规格参数 +

模组 IPU A300
采用云天励飞自研神经网络处理器芯片 DeepEye1000
配备 DDR4-2667,16GB,NNP 主频 1GHz
配备 DDR4-2667,16GB,NNP 主频 1GHz
支持 24 路 1080P H.264/H.265 高清视频解码
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
规格参数 +
卡 IPU X1000
采用云天励飞自研神经网络处理器芯片 DeepEye1000
配备 DDR4-2667,16GB,NNP 主频 1GHz
配备 DDR4-2667,16GB,NNP 主频 1GHz
支持 24 路 1080P H.264/H.265 高清视频解码
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
规格参数 +
卡 IPU X2000
采用云天励飞自研神经网络处理器芯片 DeepEye1000
配备 DDR4-2667,16GB,NNP 主频 1GHz
配备 DDR4-2667,16GB,NNP 主频 1GHz
支持 24 路 1080P H.264/H.265 高清视频解码
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
规格参数 +

卡 IPU X5000
面向计算机视觉的深度学习神经网络处理器芯片
支持 24 路 1080P H.264/H.265 高清视频解码
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
支持16 路高清视频结构化分析
支持 FP16 + INT16/12/8,提供 10Tops 推理加速算力
提供深度学习模型的定点化工具,提供通用模型的编译 以及部署开发SDK 套件,支持 MXnet、Caffe、TensorFlow
Pytorch 等主流算法框架
接口:PCIe 2.0 X4
典型功耗: 20W,无风扇,被动散热
尺寸:标准半高半长
规格参数 +
定制服务设计平台
CUSTOMIZED DESIGN PLATFORM

Chiplet方案
基于云天励飞
成熟的Chiplet架构的定制服务
成熟的Chiplet架构的定制服务

SOC架构平台
云天励飞依托自身DeepEdge10系列
研发成功打造了成熟的SOC架构平台
研发成功打造了成熟的SOC架构平台

国产先进工艺
云天励飞的定制服务设计平台
采用国产先进工艺
采用国产先进工艺

低功耗设计
平台支持
多电源域低功耗设计
多电源域低功耗设计

多核异构设计
设计平台可
集成多核CPU/XPU异构设计
集成多核CPU/XPU异构设计

展厅预约
提交成功!
请您耐心等待!
规格参数
提交成功!
感谢您的耐心填写,我们会尽快与您联系!
用户信息收集
提交成功!
感谢您的耐心填写,我们会尽快与您联系!